Содержание
Плейлист ELLE: музыка с подиума
Музыка
Выбор музыки для модного показа — настоящая наука. Треки, под которые модели представляют наряды из новых коллекций, должны быть яркими, запоминающимися и соответствовать философии марки. Самые модные композиции с подиумов прошедшей Недели моды в Нью-Йорке слушайте в нашем музыкальном обзоре.
Diane Von Furstenberg
The Weeknd — Earned
Женственный, нежный и вместе с тем очень сексуальный показ Diane Von Furstenberg сопровождается пропитанным эротикой саундтреком из нашумевшего фильма «Пятьдесят оттенков серого». Кажется, нет ничего более завораживающего, чем красивые девушки, прогуливающиеся по подиуму в шикарной одежде под пение сладкоголосого канадского проекта The Weeknd.
Michael Kors
Florence and The Machine — Dogs Day Are Over
Главной музыкальной идеей показа Майкла Корса стали британцы Florence and the Machine. Их мелодии наполнили новую коллекцию духом оптимизма и независимости. Мех, как главный атрибут показа, смотрится еще эффектней на фоне лозунгов Флоренс. Да и слова подобраны блестяще: Dogs Day Are Over!
Мех, как главный атрибут показа, смотрится еще эффектней на фоне лозунгов Флоренс. Да и слова подобраны блестяще: Dogs Day Are Over!
Tommy Hilfiger
Destiny’s Child — Bootylicious
«Я хотел «поженить» между собой спорт и роскошь», — так прокомментировал Томми Хилфигер свою коллекцию осень/зима 2015. В качестве саундтрека для показа он выбрал композицию группы Destiny’s Child — и не прогадал! Ведь, действительно, никто так не умел смешивать спорт и роскошь, как безбашенные девчонки Келли Роуленд и Мишель Уильямс и Бейонсе. Последняя, к слову, закрывала показ и, исполнив свою знаменитую Crazy In Love, сорвала восторженные аплодисменты гостей.
Alexander Wang
Gesaffelstein — Pursuit
Впервые мы услышали эту композицию в фильме «3 дня на убийство» больше года назад. И вот у трека от французского техно-диджея появилась вторая жизнь – на показе Alexander Wang, точно попадая в настроение новой коллекции дизайнера.
Custo Barcelona
Hot Since 82 feat. Alex Mills — Shadows
Испанцы Custo Barcelona в своей новой коллекции смешали африканские принты с музыкой в стиле house от коллектива Hot Since 82, получив в результате яркое и запоминающееся шоу. Невозможно не отметить: в любом из образов с показа вы буквально обречены стать звездой на самой модной вечеринке!
Prabal Gurung
Beck — Cellphone’s Dead
Финальный выход показа Prabal Gurung украсила композиция от лауреата музыкальной премии Grammy этого года, Бека Хэнсена. Психоделичный саундтрек обладает гипнотическим действием – под него смотреть на новую коллекцию бренда можно бесконечно!
Jason Wu
Camp Claude — Hurricanes
На показе коллекции осенне-зимнего сезона 2015 Джейсон Ву представил свое видение женщины будущего: сдержанной и очень элегантной. А в качестве музыкального сопровождения он выбрал молодую французскую группу Camp Claude во главе с ее очаровательной вокалисткой Диан Санье. Между прочим, стать автором песни, звучащей во время финального показа — большая честь и удача. Именно так и зажигаются звезды!
Между прочим, стать автором песни, звучащей во время финального показа — большая честь и удача. Именно так и зажигаются звезды!
Anna Sui
Smith Westerns — Varsity
Прекрасные валькирии — наверное, именно так можно охарактеризовать новую коллекцию Anna Sui. Скандинавская тема прослеживается не только в образах на подиуме, но и в музыкальном сопровождении шоу: в финале звучит легендарная песня Dancing Queen группы Abba в весьма оригинальной рок-обработке. Но чтобы гости показа не забыли, что они находятся в одной из модных столиц мира – Нью-Йорке – главной музыкальной темой были избраны американцы Smith Westerns с их романтичным треком Varsity. Получилось очень красиво!
Теги
- Музыка
Справочное руководство | Воспроизведение фотографий/музыки/видео через USB
- Начало
- Навигация по меню “Дом”
- Мультимедиа
- Воспроизведение фотографий/музыки/видео через USB
На телевизоре можно воспроизводить фотографии/музыку/видео с цифровой камеры/видеокамеры/смартфона Sony (в зависимости от модели)*, подключенного при помощи кабеля USB, или с запоминающего устройства USB.
- Подключите поддерживаемое устройство USB к телевизору.
- Для устройства должен быть установлен режим передачи мультимедиа (MTP).
- Нажмите HOME Выберите параметр [Фото], [Музыка] или [Видео] в меню [Мультимедиа].
- Отобразится параметр [Выбор устройства]. Выберите устройство, а затем файл или папку.
Парам. воспр.
В режиме просмотра миниатюр нажмите красную цветную кнопку для отображения списка настроек воспроизведения с USB.
Установки отображения
Нажмите OPTIONS в режиме просмотра миниатюр для отображения функции, которая позволит перейти от режима просмотра миниатюр к режиму списка.
Настройка качества изображения и звука мультимедийных файлов на USB–устройстве
Во время воспроизведения нажмите OPTIONS и выберите [Изображение] или [Звук].
Примечание
- Нажмите ///, затем нажмите для выбора и регулировки элемента.

Воспроизведение фото в виде слайд-шоу (фото)
- Нажмите зеленую кнопку в режиме просмотра миниатюр/режиме списка для запуска слайд-шоу.
Чтобы установить [Эффекты Слайд-шоу] и [Скорость слайд-шоу], нажмите OPTIONS [Парам. воспр.].
Чтобы остановить слайд-шоу, нажмите RETURN.
Примечание
-
Когда телевизор получает доступ к данным на устройстве USB, соблюдайте следующие меры.- Не выключайте телевизор.
- Не отключайте кабель USB.
- Не отключайте устройство USB.
Это может повредить данные на устройстве USB. - Компания Sony не несет ответственности за любой ущерб или потерю данных на записывающем носителе из-за сбоя подключенных устройств или телевизора.

- Файловая система на устройстве USB поддерживает стандарты FAT16, FAT32 и NTFS.
- Имя файла или папки в некоторых случаях может отображаться неправильно.
- При подключении цифровой камеры Sony установите режим USB-подключения камеры на “Авто” или “Устройство хранения”. Для получения дополнительной информации о режиме USB-подключения см. инструкции, прилагаемые к цифровой камере.
- Используйте запоминающее устройство USB, отвечающее стандартам класса устройств хранения USB.
- Если выбранный файл содержит неправильные сведения контейнера или является неполным, его будет невозможно воспроизвести.
Формат USB-фото
| Формат файла | Расширение |
|---|---|
| JPEG | *.jpg / *.jpeg |
Формат USB-музыки
| Расширение | Аудиокодек |
|---|---|
*. mp3 mp3 |
MPEG1 audio layer3 |
| *.wav | LPCM |
| DTS-CD | |
| *.wma | WMA V8 |
| *.flac | FLAC |
Формат USB-видео
AVI (*.avi)
| Видеокодек | Аудиокодек |
|---|---|
| MPEG1
MPEG2 XviD MPEG4 H.264 Motion JPEG |
PCM
MPEG1 Layer1/2 MPEG2 AAC MPEG4 AAC MPEG4 HE-AAC Dolby Digital Dolby Digital Plus WMA v8 MP3 |
ASF (*.
 wmv, *.asf)
wmv, *.asf)
| Видеокодек | Аудиокодек |
|---|---|
| WMV9
XviD VC-1 |
MP3
WMA V8 |
MP4 (*.mp4, *.mov, *.3gp)
| Видеокодек | Аудиокодек |
|---|---|
| MPEG4
H.264 H.263 Motion JPEG H.265 |
MPEG1 Layer1/2
MP3 MPEG2 AAC MPEG4 AAC MPEG4 HE-AAC AC4 OPUS |
MKV (*.mkv)
| Видеокодек | Аудиокодек |
|---|---|
| WMV v9
MPEG4 H.  264 264
VC-1 VP8 VP9 H.265 |
PCM
MPEG1 Layer1/2 MP3 MPEG2 AAC MPEG4 AAC MPEG4 HE-AAC Dolby Digital WMA v8 Dolby Digital Plus DTS FLAC VORBIS OPUS |
WebM (*.webm)
| Видеокодек | Аудиокодек |
|---|---|
| VP8
VP9 |
VORBIS
OPUS |
PS (*.
 mpg, *.mpeg, *.vro, *.vob)
mpg, *.mpeg, *.vro, *.vob)
| Видеокодек | Аудиокодек |
|---|---|
| MPEG1
MPEG2 |
MPEG1 Layer1/2
MP3 Dolby Digital Dolby Digital Plus DTS |
TS (*.ts, *.m2ts)
| Видеокодек | Аудиокодек |
|---|---|
| MPEG2
H.264 VC-1 H.265 |
MPEG1 Layer1/2
MP3 MPEG2 AAC MPEG4 AAC MPEG4 HE-AAC Dolby Digital Dolby Digital Plus DTS AC4 |
Примечание
- Воспроизведение файлов в указанных форматах не гарантируется.
 Файл может не воспроизводиться из-за недопустимых разрешений, а также по другим причинам.
Файл может не воспроизводиться из-за недопустимых разрешений, а также по другим причинам.
- Начало
- Навигация по меню “Дом”
- Мультимедиа
- Воспроизведение фотографий/музыки/видео через USB
В начало страницы
Создание музыки с помощью глубокого обучения | Исаак Тэм
Представляем новую архитектуру на основе VAE для создания новых музыкальных сэмплов
Фото Резли на Unsplash
Глубокое обучение радикально изменило области компьютерного зрения и обработки естественного языка не только в классификации, но и в генеративных задачах. , что позволяет создавать невероятно реалистичные изображения, а также искусственно созданные новостные статьи. Но как насчет области аудио — или, точнее, музыки? В этом проекте мы стремимся создать новые архитектуры нейронных сетей для создания новой музыки, используя 20 000 образцов MIDI различных жанров из набора данных Lakh Piano Dataset, популярного эталонного набора данных для недавних задач создания музыки.
Этот проект был совместной работой Исаака Тэма и Мэтью Кима , студентов старших курсов Пенсильванского университета.
Предыстория
Генерация музыки с использованием методов глубокого обучения была предметом интереса в течение последних двух десятилетий. Музыка оказывается другой проблемой по сравнению с изображениями, среди трех основных измерений: во-первых, музыка временна, с иерархической структурой и зависимостями во времени. Во-вторых, музыка состоит из множества инструментов, которые взаимозависимы и раскрываются во времени. В-третьих, музыка сгруппирована в аккорды, арпеджио и мелодии — следовательно, каждый временной шаг может иметь несколько выходов.
Однако у аудиоданных есть несколько свойств, которые делают их в некотором смысле похожими на то, что обычно изучается в области глубокого обучения (компьютерное зрение и обработка естественного языка, или НЛП). Последовательный характер музыки напоминает нам НЛП, для которого мы можем использовать рекуррентные нейронные сети. Есть также несколько «каналов» звука (с точки зрения тонов и инструментов), которые напоминают изображения, для которых можно использовать сверточные нейронные сети. Кроме того, глубокие генеративные модели — это новые захватывающие области исследований, способные создавать реалистичные синтетические данные. Некоторыми примерами являются вариационные автоэнкодеры (VAE) и генеративно-состязательные сети (GAN), а также языковые модели в НЛП.
Есть также несколько «каналов» звука (с точки зрения тонов и инструментов), которые напоминают изображения, для которых можно использовать сверточные нейронные сети. Кроме того, глубокие генеративные модели — это новые захватывающие области исследований, способные создавать реалистичные синтетические данные. Некоторыми примерами являются вариационные автоэнкодеры (VAE) и генеративно-состязательные сети (GAN), а также языковые модели в НЛП.
В большинстве ранних методов создания музыки использовались рекуррентные нейронные сети (RNN), которые естественным образом включают временные зависимости. Скули (2017) использовал LSTM для создания музыки для одного инструмента так же, как языковые модели. Этот же метод использовал Нельсон (2020), который адаптировал его для создания музыки в стиле lo-fi.
Недавно сверточные нейронные сети (CNN) с большим успехом использовались для создания музыки, а DeepMind в 2016 году продемонстрировал эффективность WaveNet, который использует расширенные свертки для создания необработанного звука. Ян (2017) создал MidiNet, который использует Deep Convolutional Generative Adversarial Networks (DCGAN) для создания музыкальных последовательностей с несколькими инструментами, которые могут быть обусловлены как музыкой предыдущего такта, так и аккордом текущего такта. Концепция GAN была развита Донгом в 2017 году с MuseGAN, который использует несколько генераторов для создания синтетической музыки с несколькими инструментами, которая учитывает зависимости между инструментами. Донг использовал Wasserstein-GAN с Gradient Penalty (WGAN-GP) для большей стабильности тренировок.
Ян (2017) создал MidiNet, который использует Deep Convolutional Generative Adversarial Networks (DCGAN) для создания музыкальных последовательностей с несколькими инструментами, которые могут быть обусловлены как музыкой предыдущего такта, так и аккордом текущего такта. Концепция GAN была развита Донгом в 2017 году с MuseGAN, который использует несколько генераторов для создания синтетической музыки с несколькими инструментами, которая учитывает зависимости между инструментами. Донг использовал Wasserstein-GAN с Gradient Penalty (WGAN-GP) для большей стабильности тренировок.
Наконец, поскольку последние достижения в НЛП были достигнуты с помощью сетей внимания и преобразователей, были также предприняты попытки применить преобразователи для создания музыки. Шоу (2019) создал MusicAutobot, который использует комбинацию BERT, Transformer-XL и Seq2Seq для создания многозадачного движка, который может как генерировать новую музыку, так и создавать гармонию, зависящую от других инструментов.
Набор данных
Наши данные взяты из набора данных Lakh Pianoroll, коллекции из 174 154 многодорожечных пианороллов, полученных из набора данных Lakh MIDI, и курировались Лабораторией музыки и искусственного интеллекта в Исследовательском центре ИТ-инноваций, Academia Sinica. Мы использовали версию набора данных LPD-5, которая включает треки для фортепиано, ударных, гитары, баса и струнных, что позволяет нам создавать сложную и насыщенную музыку и демонстрировать способность наших генеративных моделей аранжировать музыку на разных инструментах. Мы использовали очищенное подмножество набора данных Lakh Pianoroll, которое включает 21 245 MIDI-файлов. Каждый из файлов имел соответствующие метаданные, что позволяло нам определить информацию о каждом файле, такую как имя исполнителя и название.
Базовый метод: прогнозирование следующей ноты с помощью RNN
Чтобы установить базовый уровень генерации музыки, который мы можем улучшить, мы использовали рекуррентные нейронные сети (RNN), существующий и легко воспроизводимый метод. Генерация музыки формулируется как задача предсказания следующей ноты. (Этот метод очень похож на рекуррентные языковые модели, которые используются в НЛП. Щелкните здесь, чтобы получить дополнительную информацию.) Это позволит нам генерировать столько музыки, сколько мы хотим, непрерывно передавая сгенерированную ноту обратно в модель.
Генерация музыки формулируется как задача предсказания следующей ноты. (Этот метод очень похож на рекуррентные языковые модели, которые используются в НЛП. Щелкните здесь, чтобы получить дополнительную информацию.) Это позволит нам генерировать столько музыки, сколько мы хотим, непрерывно передавая сгенерированную ноту обратно в модель.
Что касается реализации, мы использовали Gated Recurrent Unit (GRU) вместо обычного RNN из-за его лучшей способности сохранять долгосрочные зависимости. Каждый GRU будет принимать активацию и вывод предыдущего уровня в качестве входных данных, а выходным сигналом будет следующая нота с учетом предыдущей активации и ввода.
Чтобы создать данные, необходимые для обучения нашей рекуррентной нейронной сети, мы сначала проанализировали фортепианные ноты нашего набора данных, представив каждый файл в виде списка нот, найденных в файле. Затем мы создали обучающие входные последовательности, взяв подмножества представления списка для каждой песни, и создали соответствующие обучающие выходные последовательности, просто взяв следующую ноту каждого подмножества.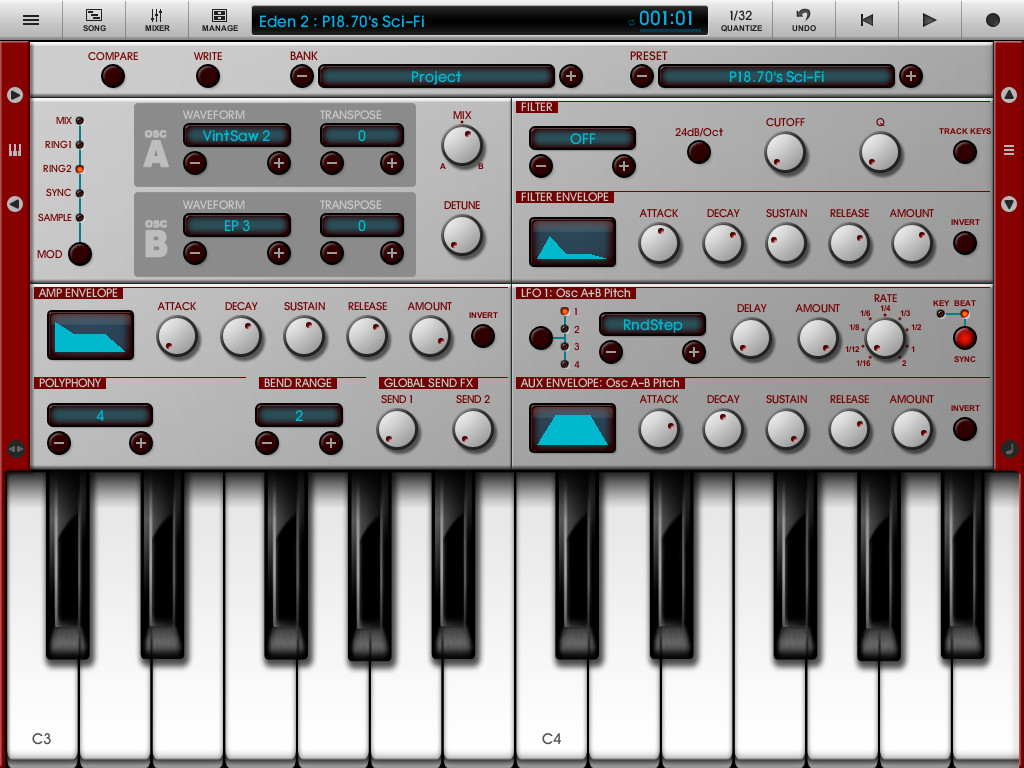 С помощью этих обучающих входных и выходных данных модель будет обучена прогнозировать следующую ноту, что затем позволит нам передать любую последовательность нот и получить прогноз следующей ноты. Каждая входная последовательность передавалась во встроенный слой, который создавал вложения размером 96. Затем это вложение передавалось в вентилируемый рекуррентный блок с одним слоем, который затем передавался в полносвязный слой для вывода распределения вероятностей следующей заметки. Мы могли бы выбрать ноту с наибольшей вероятностью в качестве следующей предсказанной ноты, но это привело бы к детерминированным последовательностям без вариаций. Следовательно, мы выбираем следующую ноту из полиномиального распределения с выходными вероятностями.
С помощью этих обучающих входных и выходных данных модель будет обучена прогнозировать следующую ноту, что затем позволит нам передать любую последовательность нот и получить прогноз следующей ноты. Каждая входная последовательность передавалась во встроенный слой, который создавал вложения размером 96. Затем это вложение передавалось в вентилируемый рекуррентный блок с одним слоем, который затем передавался в полносвязный слой для вывода распределения вероятностей следующей заметки. Мы могли бы выбрать ноту с наибольшей вероятностью в качестве следующей предсказанной ноты, но это привело бы к детерминированным последовательностям без вариаций. Следовательно, мы выбираем следующую ноту из полиномиального распределения с выходными вероятностями.
В то время как модель предсказания следующей ноты RNN проста и понятна в реализации, сгенерированная музыка звучит далеко не идеально, и ее полезность очень ограничена. Поскольку мы кодируем каждую отдельную ноту в токен и предсказываем распределение вероятностей по кодировкам, мы действительно можем сделать это только для одного инструмента, потому что для нескольких инструментов количество комбинаций нот увеличивается экспоненциально. Кроме того, предположение о том, что все ноты имеют одинаковую длину, определенно не отражает большинство музыкальных произведений.
Кроме того, предположение о том, что все ноты имеют одинаковую длину, определенно не отражает большинство музыкальных произведений.
Сгенерированная музыка для модели предсказания следующей ноты RNN
Многоинструментальная RNN
Поэтому мы стремились изучить другие методы создания музыки для нескольких инструментов одновременно и придумали Многоинструментальная RNN.
Вместо того, чтобы кодировать музыку в уникальные ноты/аккорды, как мы делали в первоначальной идее, мы работали напрямую с мультиинструментальным роялем 5 x 128 на каждом временном шаге, сглаживая его, чтобы он стал 640-мерным вектором, который представляет музыку на каждом временном шаге. Затем мы обучили RNN предсказывать 640-мерный вектор следующего временного шага, учитывая предыдущую последовательность 640-мерных векторов длиной 32.
Хотя этот метод теоретически имел бы смысл, было сложно получить удовлетворительные результаты из-за сложности получения разнообразия, дополняющего все инструменты.
- В настройке с одним инструментом мы выбрали полиномиальное распределение с вероятностью, взвешенной по выходным баллам softmax, для создания следующей заметки. Однако, поскольку все инструменты размещены вместе в 640-мерном векторе, генерация следующей ноты с использованием партитур softmaxed по всему вектору 640d может означать, что некоторые инструменты потенциально могут иметь несколько нот, а некоторые — ни одного.
- Мы попытались решить эту проблему, запустив функцию softmax отдельно для каждого из 128-мерных векторов 5 инструментов, чтобы убедиться, что мы генерируем определенное количество нот для каждого инструмента.
- Однако это означало, что отбор проб для каждого прибора был независимым друг от друга. Это означает, что сгенерированная последовательность фортепиано не будет дополнять последовательности других инструментов. Например, если из последовательности семплируется аккорд C-E-G, бас не может его включить и может сэмплировать аккорд D-F-A, который гармонически диссонирует и не дополняет.

· Кроме того, существовала проблема, связанная с незнанием того, сколько нот нужно сэмплировать для каждого инструмента в каждый момент времени. Эта проблема отсутствовала в настройке с одним инструментом, потому что отдельные ноты и аккорды из нескольких нот кодируются как целочисленные представления. Мы решили эту проблему путем выборки определенного количества нот для каждого временного шага (например, 2 для фортепиано, 3 для гитары) из полинома. Но это не увенчалось успехом, поскольку сгенерированная музыка звучала очень случайным и немузыкальным.
Создана музыка для многоинструментальной модели RNN
Переход от рекуррентной к сверточной
С этого момента мы решили сосредоточиться на сверточных нейронных сетях (CNN) , а не RNN для создания музыкальных последовательностей. CNN будет напрямую генерировать последовательность длиной 32, выводя трехмерный тензор 5 x 32 x 128. Это решило бы проблему незнания того, сколько заметок генерировать, и необходимости использовать полиномиальную выборку. Было показано, что архитектуры CNN, такие как WaveNet, обеспечивают такую же хорошую, если не лучшую производительность, как RNN при генерации последовательностей. Кроме того, их намного быстрее обучать благодаря оптимизации производительности с помощью сверточных операций.
Было показано, что архитектуры CNN, такие как WaveNet, обеспечивают такую же хорошую, если не лучшую производительность, как RNN при генерации последовательностей. Кроме того, их намного быстрее обучать благодаря оптимизации производительности с помощью сверточных операций.
MelodyCNN и Conditional HarmonyCNN
Чтобы сгенерировать несколько инструментальных дорожек, совместимых друг с другом, мы попробовали модель генерации из двух частей, которая включает MelodyCNN для генерации мелодии следующего шага по времени, а также Conditional-HarmonyCNN для создания инструментов, отличных от фортепиано, с учетом мелодии для того же временного шага, а также музыки этого инструмента для последнего временного шага.
Архитектура MelodyCNN + Conditional HarmonyCNN, используемая для создания музыки. ( Изображение автора )
Поскольку размеры входного и выходного данных одинаковы (32 x 128), используемая архитектура MelodyCNN была симметричной, с 3 сверточными слоями, 3 плотными слоями и 3 деконволюционными слоями. Условная HarmonyCNN использовала 3 сверточных слоя для каждого из входных данных (фортепиано и предыдущего инструмента), затем объединила полученные тензоры перед прохождением через плотные и деконволюционные слои.
Условная HarmonyCNN использовала 3 сверточных слоя для каждого из входных данных (фортепиано и предыдущего инструмента), затем объединила полученные тензоры перед прохождением через плотные и деконволюционные слои.
Таким образом, MelodyCNN изучает отображение между последовательностями фортепиано в последовательных временных шагах, в то время как Conditional HarmonyCNN отображает пространство фортепианной музыки на другие инструменты.
Используя в общей сложности 5 CNN (по одной для каждого инструмента), новую музыку можно генерировать итеративно, учитывая начальную последовательность с несколькими инструментами. Во-первых, MelodyCNN используется для предсказания следующей последовательности фортепиано, а Conditional HarmonyCNN используются для предсказания других инструментов.
Pianoroll музыки, сгенерированной MelodyCNN + Conditional Harmony CNN. ( Изображение автора )
Этот фреймворк успешно генерировал многоинструментальные музыкальные последовательности, в которых инструменты звучат музыкально дополняюще. Однако изменение начальной последовательности, из которой генерируется музыка, привело к очень небольшим изменениям в сгенерированной музыке, как показано на пианино выше: три сгенерированные последовательности почти идентичны друг другу.
Однако изменение начальной последовательности, из которой генерируется музыка, привело к очень небольшим изменениям в сгенерированной музыке, как показано на пианино выше: три сгенерированные последовательности почти идентичны друг другу.
Это показывает, что CNN, вероятно, сошлись при выводе только небольшого подмножества общих последовательностей в обучающих данных, что минимизировало потери при обучении. Необходимо найти другой метод для создания некоторого разнообразия в выходной музыке при одинаковых входных данных, и для этого мы обратимся к VAE.
Сгенерированная музыка для модели Melody CNN + Conditional Harmony CNN
Использование вариационных автоэнкодеров (VAE)
Предыстория VAE
Вариационный автоэнкодер (VAE) — это автоэнкодер, в котором обучение упорядочено, чтобы гарантировать, что скрытое пространство обладает хорошими свойствами, позволяющими осуществлять генеративный процесс. Двумя такими свойствами являются непрерывность — близкие точки в скрытом пространстве должны давать аналогичные точки после декодирования, и полнота — точка, выбранная из скрытого пространства, должна давать значимое содержимое после декодирования.
Стандартный автоэнкодер кодирует входные данные в вектор в скрытом пространстве, но не гарантирует, что скрытое пространство удовлетворяет непрерывности и полноте, что позволяет генерировать новые данные. Напротив, VAE кодирует ввод как распределение по скрытому пространству. В частности, мы предполагаем, что скрытое распределение распределено по Гауссу, поэтому кодировщик, кодирующий распределение, эквивалентен кодировщику, выдающему параметры среднего и стандартного отклонения нормального распределения.
Для обучения VAE используется двухчленная функция потерь: ошибка реконструкции (разница между декодированными выходами и входами), а также член регуляризации (KL-расхождение между скрытым распределением и стандартным гауссовским) для регуляризации скрытого распределение должно быть как можно ближе к стандартному нормальному.
Иллюстрация того, как работает вариационный автоэнкодер (VAE). (Изображение автора)
Приложение
Таким образом, мы применяем VAE к задаче создания музыки. Предыдущий ввод пианино кодируется VAE пианино в скрытую кодировку пианино размерности K, zₜ. Затем к средним параметрам закодированного скрытого распределения добавляется случайный шум. Стандартное отклонение этого случайного шума является гиперпараметром, который пользователь может настраивать в зависимости от желаемой вариации. Скрытые параметры zₜ затем вводятся в MelodyNN, многослойный персептрон, который изучает отображение скрытого распределения предыдущей последовательности фортепиано на скрытое распределение следующей последовательности фортепиано. Выход z_t+1 затем декодируется, чтобы стать следующим выходом фортепиано.
Предыдущий ввод пианино кодируется VAE пианино в скрытую кодировку пианино размерности K, zₜ. Затем к средним параметрам закодированного скрытого распределения добавляется случайный шум. Стандартное отклонение этого случайного шума является гиперпараметром, который пользователь может настраивать в зависимости от желаемой вариации. Скрытые параметры zₜ затем вводятся в MelodyNN, многослойный персептрон, который изучает отображение скрытого распределения предыдущей последовательности фортепиано на скрытое распределение следующей последовательности фортепиано. Выход z_t+1 затем декодируется, чтобы стать следующим выходом фортепиано.
VAE для конкретных инструментов также обучаются игре на других четырех инструментах (гитара, бас, струнные, барабаны).
Затем, аналогично ConditionalCNN ранее, мы используем ConditionalNN, еще один MLP, который принимает сгенерированные скрытые параметры фортепиано следующего периода, а также латентные параметры гитары предыдущего периода z_t+1, и изучает отображение на следующий- скрытые параметры периодической гитары w_t+1. Затем w_t+1 декодируется декодером VAE для конкретного инструмента для получения гитарного выхода следующего периода. Обучаются 4 ConditionalNN, по одному для каждого инструмента, отличного от фортепиано, что позволяет генерировать следующую последовательность из 5 инструментов.
Затем w_t+1 декодируется декодером VAE для конкретного инструмента для получения гитарного выхода следующего периода. Обучаются 4 ConditionalNN, по одному для каждого инструмента, отличного от фортепиано, что позволяет генерировать следующую последовательность из 5 инструментов.
Следовательно, сопоставляя музыкальные входные данные со скрытыми распределениями с помощью VAE, мы можем внести изменения в сгенерированный музыкальный выход, добавив случайный шум к параметрам закодированного скрытого распределения. Из-за непрерывности это гарантирует, что после добавления случайного шума декодированные входные данные будут похожи, но отличаются от исходных входных данных, а из-за полноты это гарантирует, что они дают значимые музыкальные выходные данные, аналогичные входному распределению музыки.
Визуальное руководство по архитектуре показано ниже.
Архитектура VAE-NN, используемая для создания музыки. ( Изображение автора )
Результаты
Два пианоролла, сгенерированные из одной и той же начальной последовательности. Один пример изменения, показанного в музыкальном выводе, показан выше. Оба вышеприведенных трека имели одинаковую начальную последовательность, но сгенерированные барабанные ритмы немного отличались. Кроме того, первая дорожка имела фортепианную секцию ближе к концу, а вторая — нет, и условные нейронные сети реагировали, изменяя сгенерированные сопровождающие инструментальные дорожки. (Изображение автора) 9Обучено 0002 ВАЭ латентной размерности 8, 16, 32 и 64. В конце концов, для обучения условных нейронных сетей было использовано 16-мерное скрытое пространство, поскольку музыкальные сэмплы в музыкальном пространстве относительно редки.
Один пример изменения, показанного в музыкальном выводе, показан выше. Оба вышеприведенных трека имели одинаковую начальную последовательность, но сгенерированные барабанные ритмы немного отличались. Кроме того, первая дорожка имела фортепианную секцию ближе к концу, а вторая — нет, и условные нейронные сети реагировали, изменяя сгенерированные сопровождающие инструментальные дорожки. (Изображение автора) 9Обучено 0002 ВАЭ латентной размерности 8, 16, 32 и 64. В конце концов, для обучения условных нейронных сетей было использовано 16-мерное скрытое пространство, поскольку музыкальные сэмплы в музыкальном пространстве относительно редки.
После обучения условных нейронных сетей мы обнаруживаем, что метод VAE+NN успешно используется для создания выходных сигналов с использованием нескольких инструментов, которые звучат связно, а также имеют соответствующее количество вариаций, чтобы они были эстетически привлекательными. Было обнаружено, что случайный шум со стандартными отклонениями от 0,5 до 1,0 создает наилучшую степень вариации.
Несколько хороших примеров музыки, сгенерированной с помощью VAE-NN.
Создание музыки в определенных стилях
Метод создания музыки в зависимости от определенных стилей (Изображение автора)
Объясненная выше структура VAE-NN позволяет нам напрямую создавать музыку на основе определенных стилей, таких как определенный исполнитель, жанр , или год. Например, если бы мы хотели сгенерировать музыку в стиле Thriller Майкла Джексона, мы могли бы:
1. Разбить песню на 32-шаговые последовательности и закодировать пианоролл каждой последовательности в скрытое пространство, используя кодировщик VAE каждого инструмента. Храните уникальные последовательности в установить для каждого прибора.
2. При создании музыки из стартовой последовательности из этого набора выбирается один скрытый вектор на инструмент. Этот выбранный скрытый вектор (из нашей желаемой песни) s затем интерполируется со скрытым вектором предыдущей последовательности для создания нового скрытого вектора,
, где α представляет собой латентный фактор выборки , который является гиперпараметром, который можно настроить. . (Выберите более высокие значения α для сгенерированной музыки, чтобы она в большей степени соответствовала желаемому стилю)
. (Выберите более высокие значения α для сгенерированной музыки, чтобы она в большей степени соответствовала желаемому стилю)
3. Используйте z’ₜ вместо zₜ в качестве входных данных для MelodyNN, чтобы сгенерировать новый скрытый вектор и, следовательно, сгенерированную последовательность фортепиано.
Используя этот метод и α = 0,5, мы сгенерировали новую музыку на основе нескольких песен, например, Thriller Майкла Джексона и I Want It That Way Backstreet Boys. Это позволило создать аудиосэмплы, которые имеют некоторое сходство с оригинальной песней, но также с некоторыми вариациями. (Еще раз, степень вариации может быть настроена с помощью шум_сд гиперпараметр). Можно даже создавать музыку на основе сэмплов, представляющих собой гибрид разных исполнителей или стилей, что позволяет любителям музыки синтезировать музыку, сочетающую стили разных музыкальных звезд.
Музыка сгенерирована с использованием стиля VAE-NN.
Ошибки: GAN
Вдохновленные успехом MidiNet, который использовал Deep Convolutional Generative Adversarial Networks (DCGAN) для создания реалистично звучащей музыки, мы попытались использовать GAN также для создания музыки. Известно, что GAN генерируют очень реалистичные синтетические образцы в области компьютерного зрения лучше, чем VAE. Это связано с тем, что GAN не оценивают явную плотность вероятности базового распределения, в то время как VAE пытаются оптимизировать нижнюю границу вариации. Однако известно, что GAN очень трудно успешно обучать.
Известно, что GAN генерируют очень реалистичные синтетические образцы в области компьютерного зрения лучше, чем VAE. Это связано с тем, что GAN не оценивают явную плотность вероятности базового распределения, в то время как VAE пытаются оптимизировать нижнюю границу вариации. Однако известно, что GAN очень трудно успешно обучать.
Мы использовали генератор с 6 деконволюционными слоями, взяв 100-мерный вектор шума и сгенерировав многоинструментальную музыкальную последовательность 5 x 32 x 128. Дискриминатор имеет противоположную архитектуру: он принимает музыкальную последовательность 5 x 32 x 128, пропускает ее через 6 сверточных слоев и выводит вероятность того, что образец является реальным.
Как для генератора, так и для дискриминатора использовалась активация PReLU, а также пакетная нормализация для сверточных слоев. Для обоих использовался оптимизатор Adam.
Для повышения стабильности GAN были предприняты следующие методы:
- Сглаживание меток: вместо использования жестких меток 0 или 1 для сгенерированных или реальных изображений соответственно мы добавляем к метке случайный шум (чтобы сгенерированные изображения имеют метку от 0 до 0,1, а реальные изображения имеют метку от 0,9 до 1).

- Сопоставление функций: добавление регуляризаторов L2 для обеспечения близкого распределения реальных и сгенерированных данных. Использовались два регуляризатора: первый на абсолютной разнице ожидаемого значения входных данных реального и сгенерированного изображения, а второй — на абсолютной разнице ожидаемого значения выходных данных первого сверточного слоя для входных данных реального и сгенерированного изображений.
- Правило обновления двух масштабов времени (TTUR): использование более высокой скорости обучения для дискриминатора по сравнению с генератором.
- Настройка скорости обучения
Несмотря на несколько попыток, обучение GAN оказалось безуспешным для создания разнообразной реалистично звучащей музыки. Были случаи коллапса режима, такие как сгенерированный звуковой образец ниже, который представляет собой 100 сэмплов, сгенерированных из разных векторов шума, объединенных вместе. Сгенерированные образцы в основном похожи. Другие попытки не привели к чему-либо существенному.
Ошибки неудачного эксперимента GAN
Еще одна базовая линия: Трансформеры
Второй, более сложный базовый метод, который мы использовали, — это архитектура трансформатора. Трансформеры добились больших успехов в НЛП, способные тренироваться гораздо быстрее и обладающие гораздо лучшей долговременной памятью, чем старые языковые модели, основанные на повторениях. Мы использовали архитектуру Transformer-XL проекта Music Autobot из-за ее чрезвычайно воспроизводимого кода — мы благодарим Эндрю Шоу за это и рекомендуем вам ознакомиться с его блестящей серией статей!
В обычной модели трансформатора прямые соединения между блоками данных дают возможность зафиксировать долгосрочные зависимости. Однако эти ванильные преобразователи реализованы с контекстом фиксированной длины, поэтому преобразователи не могут моделировать зависимости, длина которых превышает фиксированную длину, и происходит фрагментация контекста.
Архитектура Transformer-XL предоставляет методы для решения этих проблем. Во-первых, он имеет механизм повторения на уровне сегмента. Во время обучения представления, вычисленные для предыдущего сегмента, кэшируются, чтобы их можно было использовать в качестве расширенного контекста, когда модель обрабатывает следующий сегмент. Таким образом, теперь информация может проходить через границы сегментов, а также решает проблему фрагментации контекста. Во-вторых, он имеет схему относительного позиционного кодирования. Это позволяет модели понимать не только абсолютное положение каждой лексемы, но и положение каждой лексемы относительно друг друга, что чрезвычайно важно в музыке.
Во-первых, он имеет механизм повторения на уровне сегмента. Во время обучения представления, вычисленные для предыдущего сегмента, кэшируются, чтобы их можно было использовать в качестве расширенного контекста, когда модель обрабатывает следующий сегмент. Таким образом, теперь информация может проходить через границы сегментов, а также решает проблему фрагментации контекста. Во-вторых, он имеет схему относительного позиционного кодирования. Это позволяет модели понимать не только абсолютное положение каждой лексемы, но и положение каждой лексемы относительно друг друга, что чрезвычайно важно в музыке.
В отличие от текста, токенизация музыки намного сложнее. Одна музыкальная нота представляет два разных значения — высоту тона и продолжительность (она также может представлять многие другие вещи, такие как громкость и синхронизация, но они менее важны для наших целей). В результате каждая заметка должна быть закодирована в последовательность токенов. К счастью, проект Music Autobot занимается токенизацией MIDI-файлов.
Мы также находим сгенерированную музыку относительно хорошей — проверьте ее ниже!
Выход Майкла Джексона
Потоковая передача Майкла Джексона Исаака на ПК и мобильных устройствах. Слушайте более 265 миллионов треков бесплатно на SoundCloud.
soundcloud.com
Заключение
В целом, мы внедрили различные методы глубокого обучения для решения проблемы создания музыки с разным уровнем успеха. В нашем базовом методе использовалась модель рекуррентной нейронной сети как для одного трека, так и для нескольких треков. Хотя эта модель добилась большего успеха в отношении музыкальности воспроизводимых нот, ее полезность была очень ограничена, поскольку она могла воспроизводить ноты только на четвертных долях. Затем мы перешли к модели сверточной нейронной сети, используя ванильную CNN для создания фортепианной дорожки и условную CNN, которая использовала фортепианную дорожку для создания дорожек других инструментов. Мы обнаружили, что схемы, созданные моделями CNN, были гораздо более правильными и последовательными, потому что мы использовали условные модели.
Разработанная нами новая архитектура на основе VAE стала наиболее успешным вкладом в наш проект. Кодируя последовательности в скрытое пространство с помощью VAE, мы можем затем добавить шум в скрытое пространство, чтобы увеличить вариацию генерируемого вывода контролируемым образом, сохраняя при этом сходство между предыдущими последовательностями, в конечном итоге улучшая уникальность нашей сгенерированной музыки.
Вы можете найти весь наш код в нашем репозитории Github — не стесняйтесь использовать его для своих собственных приключений по созданию музыки. Оставьте комментарий или свяжитесь со мной лично на LinkedIn, если у вас есть какие-либо вопросы, и я буду рад помочь!
Что действительно делает область глубокого обучения удивительной, так это культура совместной работы с открытым исходным кодом — наша работа никогда не была бы возможна без множества щедрых участников до нас, и мы надеемся, что этот проект был небольшим, но значимым вкладом в пространство глубокого обучения. .
.
Особая благодарность профессорам Лайлу Ангару и Конраду Кордингу, которые читали этот курс по глубокому обучению (CIS522 — Глубокое обучение в науке о данных в Университете Пенсильвании), а также консультанту TA Pooja за ее руководство в течение всего семестра.
Приложение 3: Принципы моделей ввода-вывода
Принципы моделей ввода-вывода кратко описаны здесь. Существенной особенностью является то, что продукция любой отрасли не реализуется целиком на рынке продукта отрасли; некоторая его часть будет использоваться отраслями, связанными с производственной цепочкой, в качестве ресурсов для производства; примером может служить продукция промышленности листового металла, которая будет в значительной степени закупаться производителями автомобилей и бытовой техники в качестве сырья для производства автомобилей и холодильников. Более важными местными примерами являются продукция сельскохозяйственной промышленности, которая обеспечивает ресурсы для производства продуктов питания и напитков, производства молочных продуктов и поддерживает производство кондитерских изделий и молочных продуктов; древесина, заготовленная лесхозами, продается лесопромышленникам; в то время как добыча полезных ископаемых является вкладом в перерабатывающую промышленность. Эта структура обратной и прямой связи является важной характеристикой таблицы ввода-вывода и определяет ее набор межотраслевых отношений.
Эта структура обратной и прямой связи является важной характеристикой таблицы ввода-вывода и определяет ее набор межотраслевых отношений.
Разработка модели ввода-вывода, применяемой в этом анализе, основана на таблице транзакций, разработанной АБС, со следующей структурой:
- Каждая строка показывает распределение одной отрасли по другим отраслям и конечному спросу, в В столбце указаны отрасли в вопросах приобретения ресурсов из других отраслей экономики. Они называются «промежуточными покупками», чтобы отличить их от окончательных покупок/продаж.
- Таблица содержит четыре квадранта:
- Обрабатывающий сектор показан как Квадрант 1 и отражает поток товаров и услуг между отдельными отраслями в течение года.
- Во втором квадранте регистрируются потребительские расходы конечных покупателей и других секторов промышленности, в которых они производятся. Особенностью квадранта 2 является наличие статей капитала, которые включены в общие расходы отдельных отраслей, однако эти капитальные товары не используются для производства в текущем периоде, и поэтому они показаны для производственного сектора.
 Только.
Только. - Квадрант 3 регистрирует платежи за использование первичных ресурсов, в частности, для труда (заработная плата, зарегистрированная как вознаграждение работникам), корпорациям как прибыль или рента (валовой операционный излишек), правительствам различных уровней как косвенные налоги и сборы, а также импортерам. . Стоимость, добавленная каждой отраслью к общему национальному доходу, валовому внутреннему продукту или государственному продукту, измеренная по факторным (затратным) затратам, представляет собой комбинацию некоторых из этих платежей следующим образом:
Добавленная стоимость i = WSS i + GOS i + Косвенные налоги i – субсидии i
- наемных работников ( COE i ), выплаченных рабочей силе, валовой операционный доход ( GOS i ) плюс косвенные налоги и сборы за вычетом субсидий, выплачиваемых государством промышленности i.
 Сумма всей добавленной стоимости i отраслей, составляющих экономику, составляет величину национального дохода Австралии, а именно ВВП (квадрант 4).
Сумма всей добавленной стоимости i отраслей, составляющих экономику, составляет величину национального дохода Австралии, а именно ВВП (квадрант 4).
Одной из целей моделирования является определение того, насколько увеличится ВВП в ответ на расходы проекта XXX и в ответ на увеличение расходов людей в ответ на проект XXX, например увеличение туризма.
В наш анализ мы также включили промежуточную таблицу (с матричным идентификатором Z), которая показывает, какая часть общего предложения продукции отрасли удовлетворяется данной отраслью. Это необходимо в связи с тем, что суммарные отрасли производят товары, которые измеряются как часть другого сектора (например, сектор «Другие отрасли», производящий услуги, которые регистрируются как «Личные услуги»). На данном этапе мы также исключаем утечку, связанную с импортом. Это происходит, когда спрос приводит к тому, что продукция определенного сектора импортируется из-за границы.
Математика моделирования ввода/вывода
Таблица транзакций может быть представлена в следующей матричной форме, где X ij – объем продукции отрасли j, закупаемой отраслью i в качестве входных данных, а D i – конечный спрос. для промышленности я выпуска.
для промышленности я выпуска.
Приведенная выше таблица транзакций определяется путем деления элементов приведенной выше матрицы на текущую стоимость продукции отрасли i. По этому определению:
Эти a ij являются техническими коэффициентами производства, и они представляют объем продукции отрасли i, необходимый для производства единицы продукции отрасли j.
Из (1) можно написать:
и выпуск для отрасли i представляет собой сумму промежуточных продаж и закупок плюс конечный спрос на выпуск i (D i ) следующим образом:
Где X — вектор выпуска продукции отрасли, D — вектор конечного спроса, а A — i xj матрица технических коэффициентов.
Выражение (3) может быть решено для X как функции D:
Вектор решения представляет выпуск отраслей как некоторое кратное конечного спроса (D) кратное представляет собой матрицу (I-A) -1 =Б. Это известно как обратный Леонтьев после его создателя. Теперь B структурирован следующим образом:
Теперь B структурирован следующим образом:
Это называется таблицей коэффициентов взаимозависимости и измеряет прямые, индуцированные и косвенные эффекты изменения конечного спроса на один из продуктов отрасли. Столбцы этой таблицы коэффициентов взаимозависимости являются выходными множителями.
Что говорят нам множители вывода ввода/вывода? Множители выпуска I/O измеряют изменения во всех выпусках отрасли, вызванные изменением конечного спроса на какой-либо один выпуск. Например, если спрос на сельскохозяйственную продукцию в Австралии увеличился на 10%, то мультипликаторы объема ввода-вывода измеряют влияние на выпуск всей отрасли, включая сельское хозяйство.
Мультипликаторы занятости описывают влияние изменения конечного спроса на продукцию конкретной отрасли на занятость в этой же и во всех других отраслях. Эти мультипликаторы занятости I/O выводятся из уравнений занятости, которые, в свою очередь, получаются путем простого умножения уравнений выпуска для каждой отрасли на отношение занятости (E i )/выпуска (X 1 ) для рассматриваемой отрасли. Таким образом, уравнение занятости для отрасли 1 находится путем умножения (1) хотя и на E и /Х 1 . Затем мультипликаторы занятости I/O находятся таким же образом путем инвертирования набора уравнений занятости, решающих для занятости в отрасли i.
Таким образом, уравнение занятости для отрасли 1 находится путем умножения (1) хотя и на E и /Х 1 . Затем мультипликаторы занятости I/O находятся таким же образом путем инвертирования набора уравнений занятости, решающих для занятости в отрасли i.
Мультипликаторы заработной платы находятся аналогичным образом, но в данном случае для их получения используются уравнения заработной платы. Мультипликатор заработной платы измеряет изменение всех доходов от заработной платы в отрасли в результате изменения любого конечного спроса.
Однако существует также эффект мультипликатора заработной платы, который эффективно «закрывает» модель по отношению к сектору домохозяйств. Мультипликатор заработной платы показывает, в какой степени увеличение дохода домохозяйства от заработной платы увеличивает расходы в сообществе, создавая тем самым дополнительную экономическую активность и занятость. Чтобы учесть влияние повышения заработной платы на расходы на конечное потребление домохозяйств (компонент конечного спроса D), мы выводим матрицу C, параллельную матрице A. Элементы матрицы C, cij относятся к ожидаемому увеличению расходов на конечное потребление домохозяйств, связанному с этим. при единичном увеличении выпуска продукции по отраслям j.
Элементы матрицы C, cij относятся к ожидаемому увеличению расходов на конечное потребление домохозяйств, связанному с этим. при единичном увеличении выпуска продукции по отраслям j.
Следовательно, конечный спрос D содержит зависимый компонент, основанный на заработной плате, и независимый компонент, который идентифицируется как FD. Мы описываем эту связь в уравнении [0.1].
Выражение [1.5] можно подставить в [1.4] при сохранении равенства следующим образом:
Тогда можно решить выражение [1.6] для равновесия X = Y как функции FD:
Вектор решения B представляет выпуск отраслей как некоторый кратный конечному спросу (FD), кратный матрице . Структура L представляет собой таблицу коэффициентов взаимозависимости и измеряет прямые, косвенные и индуцированные (в случае замкнутости модели) эффекты изменения конечного спроса на один из видов продукции отрасли. Столбцы этой таблицы взаимозависимости являются выходными множителями.
Множители ввода-вывода измеряют изменение всех выпусков отрасли, вызванное изменением конечного спроса на какой-либо один выпуск. Мультипликаторы заработной платы, добавленной стоимости и занятости рассчитываются на основе мультипликаторов выпуска. Предполагается, что связь между выпуском данного сектора и его заработной платой, добавленной стоимостью и занятостью постоянна (фактически определяется технологическими и структурными параметрами в отрасли), так что если выпуск в секторе увеличивается на заданную величину, то Влияние на добавленную стоимость, заработную плату и занятость можно рассчитать с использованием постоянного коэффициента для каждой отрасли.
Мультипликаторы заработной платы, добавленной стоимости и занятости рассчитываются на основе мультипликаторов выпуска. Предполагается, что связь между выпуском данного сектора и его заработной платой, добавленной стоимостью и занятостью постоянна (фактически определяется технологическими и структурными параметрами в отрасли), так что если выпуск в секторе увеличивается на заданную величину, то Влияние на добавленную стоимость, заработную плату и занятость можно рассчитать с использованием постоянного коэффициента для каждой отрасли.
Мультипликаторы валового государственного продукта (ВСП) измеряют вклад изменения конечного спроса в добавленную стоимость каждой отрасли или ее индивидуальный вклад в ВСП. Мультипликаторы ВСП выводятся из уравнений общего дохода, которые представляют собой уравнения выпуска, преобразованные в отношения общего дохода путем применения коэффициентов добавленной стоимости/выпуска к выпуску каждой отрасли.
Все четыре набора мультипликаторов применяются к задаче определения занятости, ВСП, заработной платы и эффектов выпуска незавершенного проекта ХХХХ.
Здесь следует различать множители Типа I и Типа II. Мультипликаторы дохода или выпуска типа I представляют собой отношение прямого плюс косвенного изменения спроса или выпуска к прямому изменению дохода в результате увеличения конечного спроса на доллары для любой данной отрасли.
Множители типа II получены математически выше и могут быть считаны из столбца матрицы B в (7). В любом случае, типа I или II, модель «затраты-выпуск» закрыта по отношению к домохозяйствам, что и имеет место в данном случае.
Практичность моделей ввода-вывода зависит от определенных свойств и допущений. Во-первых, работающая модель ввода-вывода будет математически стабильной, что произойдет, если выполняется следующее:
Таблица технических коэффициентов должна иметь хотя бы один столбец, сумма которого меньше единицы. Ни один столбец в таблице не может превышать единицу в совокупности (ни одна отрасль не может платить за свои ресурсы больше, чем она получает от продажи своей продукции).